-
Masking and padding with PytorchNatural Language Processing 2022. 2. 23. 00:25728x90반응형
아래 사이트를 참고하여 정리하는 글입니다.
Reference
https://www.tensorflow.org/guide/keras/masking_and_padding
Introduction
NLP 작업에서 텍스트는 모두 같은 길이가 아니므로 batch 처리를 위해 시퀀스의 길이를 같게 만들어야 한다. 컴퓨터는 행렬을 사용해 병렬 연산을 하므로 필수적인 작업이다. 너무 짧은 시퀀스의 경우 정해둔 최대 길이에 맞춰서 padding 처리를 해주고 너무 긴 시퀀스의 경우에는 최대 길이에 맞춰서 truncate 해줘야 한다.
Padding은 최대 길이에 맞게 시퀀스의 앞부분 혹은 마지막을 0으로 채우는 방식이다.
이렇게 padding 처리를 한 시퀀스는 아무 의미 없는 0 데이터(더미 데이터)를 포함하게 된다. 이 때, masking 작업을 통해 모델이 0이 아닌 의미 있는 데이터만을 학습하도록 한다.
Masking은 실제 데이터는 1로, 무의미한 데이터는 0으로 일종의 filter를 만들어 모델의 연산에서 무의미한 데이터를 가려주는 역할을 한다.
본 글에서는 pytorch을 사용해 padding 처리와 mask를 만들어 본다.
Padding sequence data
먼저, padding 처리를 하는 과정을 볼 것이다.
import torch import torch.nn as nn from torch.nn import functional as nnf import re시퀀스 데이터를 처리할 때 각 시퀀스가 서로 다른 길이를 가지고 있는 것은 매우 흔한 경우다.
아래 예(sentences)에서도 마찬가지이다.
sentences = ['A woman wearing a net on her head.! ', 'A woman cutting a?? large white sheet cake.', 'A woman wearing a hair net cutting a large white sheet cake.', 'there is a woman that is cutting a white cake', "A woman marking a cake with the back of a chef's knife. "]컴퓨터는 자연어를 이해하지 못하므로 시퀀스(문장)를 자연어에서 숫자로 인코딩을 해야 한다.
인코딩을 하기 위해 vocab을 만들어 준다.
# 1. 각 문장 전처리 진행(소문자로 변환, 특수 문자 제거) lower_sents = [sent.lower() for sent in sentences] preprocessed_sents = [re.sub('[.,!?\']', '', sent).strip() for sent in lower_sents]
# 2. key가 단어, value가 idx가 오도록 vocab dictionary 생성 words = list(set([word for sent in preprocessed_sents for word in sent.split(' ') if word!=''])) vocab = {word: idx+1 for idx, word in enumerate(words)} vocab['<pad>']=0
아래와 같이 인코딩하는 함수를 만들어 전처리된 문장에 적용한다.
# 한 문장을 받아 vocab을 통해 인코딩하는 함수 def sent_encoding(sent, vocab): encoded_sent = [] for token in sent.split(' '): encoded_sent.append(vocab[token]) return encoded_sent encoded_sents = [] for sent in preprocessed_sents: encoded_sents.append(sent_encoding(sent, vocab))인코딩한 결과와 각 시퀀스의 길이를 살펴보자

위의 결과를 보면 시퀀스의 길이는 모두 다른 것을 확인할 수 있다.
padding 과정은 다음과 같다.
max_seq_len = 10 # 최대 길이 padded_seqs = [] # 새롭게 패딩 처리를 한 토큰을 담기 위한 list for tokens in encoded_sents: padding = max_seq_len - len(tokens) # 최대 길이와 각 시퀀스 길이의 차이 # 최대 길이(13)보다 작거나 같은 경우 if padding >= 0 : # 차이만큼 padding 처리 new_tokens = torch.cat(( torch.tensor(tokens), torch.zeros(padding, dtype=torch.int64) )) # 최대 길이(13)보다 큰 경우 else: # 최대 길이에 맞기 자름(truncate) tokens = tokens[:max_seq_len] new_tokens = torch.tensor(tokens) padded_seqs.append(new_tokens)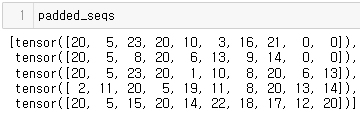
Masking
이제 모든 시퀀스의 길이가 균일하므로 모델에게 데이터의 padding된 부분을 무시하라고 알려야 한다. 이러한 메커니즘이 masking이고 그 과정은 다음과 같다.
mask_list = [] for seq in padded_seqs: # ge(1) 함수는 seq에서 1보다 크거나 같은 토큰들은 True 1보다 작으면 False를 반환함 # 즉, padding 부분은 False로 나머지는 True로 됨 mask = seq.ge(1) mask = mask.float() # float()을 통해 padding 부분은 0 나머지는 1인 mask 생성 mask_list.append(mask) 728x90반응형
728x90반응형'Natural Language Processing' 카테고리의 다른 글
Meta Llama 3.1 Review - blog (2) 2024.07.24 5 Text Decoding Techniques (0) 2022.02.24 Word2Vec (word embedding) (0) 2022.02.09 seq2seq 그리고 attention (0) 2022.02.04 기계 번역에서 alignment 의미 (0) 2022.01.25