-
Meta Llama 3.1 Review - blogNatural Language Processing 2024. 7. 24. 23:33728x90반응형
Llama 3.1 소개
- SOTA 언어 모델과 견줄 수 있는 open-source 모델
- 8B, 70B, 405B 규모의 모델 제공, 8개의 다국어 지원, 128K의 context length
모델 구조
- 15T 토큰이 넘는 Llama 3.1 405B를 학습하기 위해 전체 training stack 최적화 및 16,000개 이상의 H100 GPUs로 학습 진행
- 학습 과정
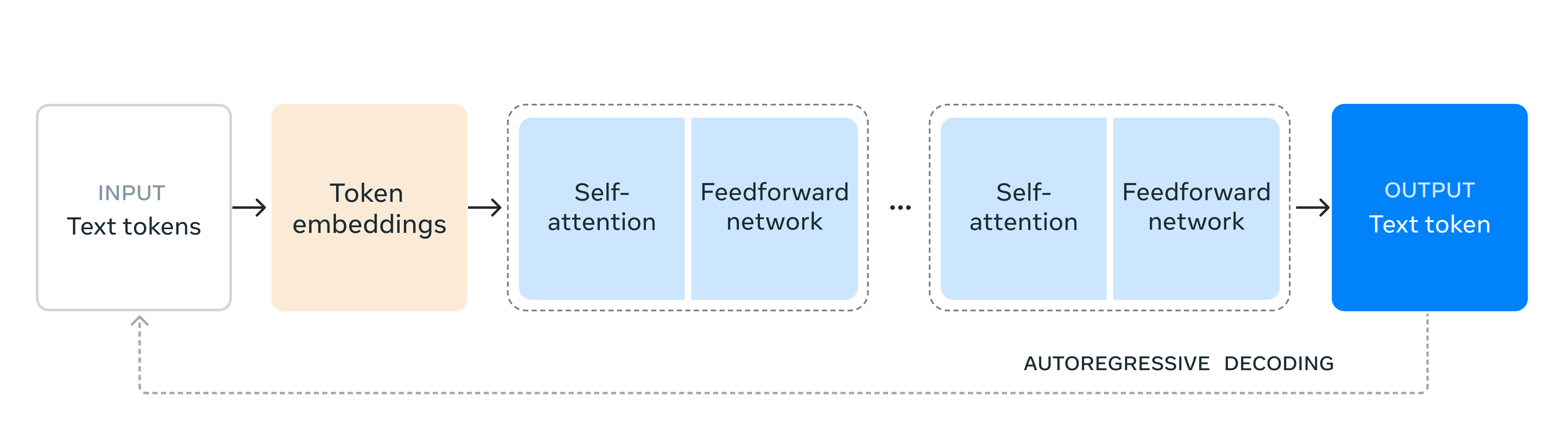
- training 안정성을 위해 MOE 모델이 아닌 약간의 수정을 거친 표준 decoder-only transformer 모델 구조를 채택
- iterative post-training 방식을 채택
- 각 round에서 SFT 및 direct preference optimization 진행. 이는 높은 품질의 합성 데이터 생성 및 성능 향상을 가능케 함
- pre- 및 post-training에서 사용할 데이터의 양과 품질 개선을 위해 다음을 적용
- pre-training data 위한 신중한 pre-processing 및 cruation 파이프라인 개발
- 엄격한 quality assurance
- post-training data 위한 filtering 접근법
- 405B 모델의 large-scale production 추론을 위해 모델을 16-bit (BF16)에서 8-bit (FP8)로 quantize 진행
Instruction 및 chat FT
- post-training에서 pre-trained 모델을 기반으로 여러 단계의 alignment 작업을 통해 최종 chat model 생성
- 각 단계에서는 SFT, RS(Rejection Sampling), DPO(Direct Preference Optimization) 적용됨
- 고품질의 합성 데이터 생성 및 전처리 기술을 통해 SFT 데이터 충당
- 고품질의 모델을 위해
- we maintain the quality of our model on short-context benchmarks, even when extending to 128K context.
- safety mitigation 추가
궁금한 점
- 전체 training stack 최적화 -> 어떤 식으로 최적화를 했을지?
- iterative post-training 방식 -> 어떤 방식인지?
- cruation 파이프라인 -> 무엇인지?
- we maintain the quality of our model on short-context benchmarks, even when extending to 128K context. -> 무슨 말인지?
의견
- 모델 구조는 decoder-only 구조가 안정적인 것 같음
- 데이터 전처리 및 필터링의 중요성
참고
728x90반응형'Natural Language Processing' 카테고리의 다른 글
5 Text Decoding Techniques (0) 2022.02.24 Masking and padding with Pytorch (0) 2022.02.23 Word2Vec (word embedding) (0) 2022.02.09 seq2seq 그리고 attention (0) 2022.02.04 기계 번역에서 alignment 의미 (0) 2022.01.25