-
seq2seq 그리고 attentionNatural Language Processing 2022. 2. 4. 23:06728x90반응형
Reference
https://guillaumegenthial.github.io/sequence-to-sequence.html
Seq2Seq with Attention and Beam Search
Sequence to Sequence basics for Neural Machine Translation using Attention and Beam Search
guillaumegenthial.github.io
1) 시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq)
이번 실습은 케라스 함수형 API에 대한 이해가 필요합니다. 함수형 API(functional API, https://wikidocs.net/38861 )에 대해서 우선 숙 ...
wikidocs.net
Vanilla Seq2Seq
- encoder-decoder 구조
- encoder는 입력 시퀀스를 인코딩하고 decoder는 타겟 시퀀스를 생성함
Encoder
- 여기서의 입력 시퀀스는 "how are you"임
- 입력 시퀀스는 토큰화를 사용해 쪼갠 후 [w0, w1, w2]로 변환(워드 임베딩을 통해 표현된 임베딩 벡터의 형태로 seq2seq)에 입력됨
- 이러한 벡터 시퀀스에 대해 LSTM을 실행하고 LSTM의 마지막 은닉 상태를 저장하며 이것이 encoder representation인 e임
- 은닉 상태를 [e0, e1, e2]로 표현. 그러면 e=e2임 (이 때의 은닉 상태 e=e2는 과거 시점의 동일한 LSTM 셀에서의 모든 은닉 상태의 값을의 영향을 누적해서 받아온 값이며 입력 시퀀스의 모든 단어 토큰들의 정보를 요약해서 담고 있다고 할 수 있음)

- 인코더의 마지막 시점의 은닉 상태(context vector, encoder representation, e, e2)를 디코더로 넘겨줌
Word Embedding
embedding을 사용하기 위해 모델이 사용하거나 읽을 수 있기를 원하는 모든 단어들을 포함하는 "vocabualry" 목록을 만들어야 한다. 모델의 입력은 시퀀스에 단어의 id를 포함하는 텐서여야 한다.
vocabulary에 포함해야 하는 네 가지 symbol이 있다.
- <PAD>: 훈련하는 동안, 샘플들을 네트워크에 공급해야 함. 네트워크에서 계산을 하기 위해 이러한 batch들의 입력은 동일한 width를 가져야 함. 그러나 샘플들은 모두 동일한 길이를 가지지 않음. 번역 문제의 경우 I love you, My name is YJ and I like a cat. 과 같이 문장의 길이가 모두 다르기 때문임. 그렇기 때문이 더 짧은 입력의 경우 batch의 동일한 width로 맞추기 위해 <PAD>로 채워줌(최대 길이를 맞추기 위해 padding 과정을 진행한다는 의미)
- <EOS>: 디코더에게 문장이 끝나는 위치를 알려줌
- <UNK>: 실제 데이터에 대해 모델을 훈련하는 경우 자주 나타나지 않는 단어들을 <UNK>로 대체하여 모델의 리소스 효율성을 개선할 수 있음
- <GO>: 디코더의 첫 번째 시작 단계에 이 토큰을 입력하며 디코더가 출력을 생성하도록 알림
Decoder
- e는 입력 시퀀스의 의미를 포착한 벡터임
- e를 사용해 타겟 시퀀스를 한 단어씩 생성함
- LSTM 셀에 은닉 상태 e와 special start token w_sos를 입력함
- LSTM은 다음 은닉 상태 h0을 계산함
- 그런 다음, Vocab 공간으로 변환하는 어떤 함수 g를 적용하여 vocab과 동일한 크기의 벡터 s0으로 변환
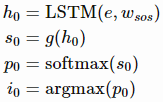
- 그런 다음, s0에 softmax를 적용해 확률 p0 벡터로 normalize함
- p0은 vocab에서의 각 단어의 확률
- 만약 "comment"이 가장 높은 확률을 가진다고 가정 =>i0 = argmax(p0)은 "comment"의 인덱스에 해당함
- w_i0 = w_comment을 얻고 절차를 다음과 같이 반복함
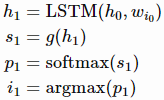
- 디코딩은 special end token을 예측했을 때 끝남

- 디코더의 첫 번째 LSTM 셀은 인코더에서 받은 context vecotr로 은닉 상태에 사용
- 디코더는 첫 번째 입력으로 special start token을 입력 받아 다음에 등장할 가장 높은 확률을 가지는 단어를 출력함(test 단계)
- 직관적으로 hidden vector는 디코딩되지 않은 "amount of meaning(의미의 양)"을 나타냄
- 위의 방법은 문장의 시작에 대해 conditionned된 next word의 분포를 모델링하는 것을 목표로 함

훈련 단계와 테스트 단계에서의 seq2seq
- 훈련 단계: 디코더는 context vector(from encoder)와 실제 정답인 <sos> je suis étudiant을 입력으로 받아 je suis étudiant <eos>를 출력하도록 훈련함 => teaching forcing
- 테스트 단계: 디코더는 context vector와 <sos> 만을 입력으로 받은 후 다음 단어를 예측하고 그 단어를 다음 시점의 LSTM에 입력하는 작업을 반복함

Seq2Seq with Attention
- Attention은 디코더의 LSTM의 hidden vector에만 의존하는 대신 디코딩 할 때 입력 시퀀스의 특정 부분에 focus 하도록 학습하는 메커니즘임
- LSTM의 입력에 새로운 벡터인 ct를 추가하여 공식을 약간 수정하면 다음과 같음

- ct는 attention(context) vector
- 각 디코딩 단계에서 새로운 context vector를 계산함
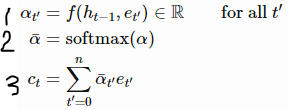
- 1: 인코더의 각 은닉 상태 et'에 대한 score 계산
- 2: softmax를 사용해 αt'의 시퀀스를 normalize
- 3: et'의 가중합인 ct 계산

- function f는 다음 중 하나를 따름
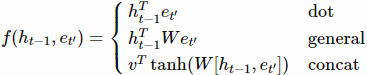
- 어텐션 가중치 α_bar는 쉽게 해석됨: vas(영어에서의 are)을 생성할 때 α_bar_are이 1에 가깝고 나머지 how or you는 0에 가까울 것이라 예상할 수 있음
- 직관적으로, context vector c는 are의 은닉 벡터와 거의 같으며 프랑스 단어 vas를 생성하는 데 도움이 됨
- 어텐션 가중치를 행렬(행=입력 시퀀스, 열=출력 시퀀스)에 넣으면 영어 문장과 프랑스어 문장 간의 alignment를 확인할 수 있음

NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE 논문의 그림 - (인코더가 입력 시퀀스를 거꾸로 처리하면 더 잘 작동함)
Training
- 첫 번째 단계에서 comment 혹은 vas를 생성해야 하는지 여부를 확신할 수 없으면 어떻게 될까?(훈련 시작 시 대부분의 경우)
- 그러면 전체 시퀀스는 엉망이 될 것이고 모델은 학습하지 못 함
- 학습 중 예측된 토큰을 다음 단계에 대한 입력으로 사용하면, 오류가 누적되고 모델이 입력의 올바른 분포에 노출되지 않아 학습이 느리거나 불가능해 짐
- 속도를 높이려면 실제 출력 시퀀스(<sos> comment vas tu)를 디코더의 LSTM에 공급하고 모든 위치에서 다음 토큰(comment vas tu <eos>)을 예측함 => teaching forcing

- 디코더는 각 시간 단계에 대해 vocab pi 확률 벡터를 출력함
- 그런 다음, 주어진 타겟 시퀀스 y1, ..., yn에 대해 각 관련된 시간 단계에서 생성되는 각 토큰의 확률의 곱으로 타겟 시퀀스의 확률을 계산할 수 있음

- 여기서 pi[yi]는 i번째 디코딩 단계에서 확률 벡터 pi의 yi번째 entry를 추출하는 것을 의미
- 특히, 실제 타겟 시퀀스의 확률을 계산할 수 있음
- 확벽한 시스템(모델)은 타겟 시퀀스에 1의 확률을 줄 것이므로, minimizing과 같은 타겟 시퀀스의 확률을 maximize하기 위해 네트워크를 훈련시킬 것임(이 부분 잘 모르겠음.............)

- 이 예에서 이는 다음과 같음
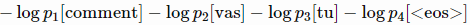
- 이것이 standard cross entropy임: 실제로 타겟 분포(모든 one-hot vectors)와 모델(vectors pi)에서 출력한 예측 분포 간의 cross entropy를 최소화 함
Decoding
- inference/testing 단계는 어떤가? 문장을 디코딩하는 다른 방법이 있는가?
- 테스팅 단계에서 디코딩을 하는 두 가지 주요 방법이 있음
- 첫 번째 방법: 이 글에서 다룬 greedy decoding임. 이전 단계에서 예측된 단어를 다름 단계로 공급하는 방식

- 하지만 이 방식은 오류가 누적될 가능성이 있음
- 모델을 훈련시킨 후에도 모델은 작은 오류를 만들 수 있음(디코딩의 첫 단계에서 comment에 대한 vas에 적은 점수를 줌)
- 디코딩을 수행하는 더 좋은 방법으로 beam search가 있음
- 최고 점수를 가지는 토큰을 예측하는 대신 k개의 hypotheses를 유지함(예를 들어 k=5에서 k는 beam size)
- 각 새로운 시간 단계에서, 5개의 hypotheses에 대해 우리는 V개의 새로운 가능한 토큰이 있음
- 총 5V개의 새로운 hypotheses를 만듦
- 그런 다음, 5개의 가장 좋은 것만 유지하고 계속 반복함
- Ht를 시간 단계 t에서 디코딩 된 hypotheses로 정의함

- 예를 들어 k=2이면 가능한 H2는 다음과 같음

- 이제 가능한 모든 새로운 토큰들을 추가하여 Ht에서 생성된 모든 가능한 candidates C_t+1를 고려함

- 그리고 k개의 가장 높은 점수(시퀀스의 확률)를 유지함
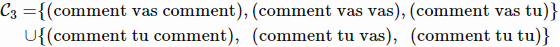
- 만약 2개의 best는 다음과 같음

- 모든 hypothesis가 <eos> 토큰에 도달하면 가장 높은 점수를 가지는 hypothesis를 반환함
- beam search를 사용하면 beam에 gold hypothesis가 유지되므로 첫 번째 단계의 작은 오류가 다음 단계에서 수정될 수 있음
Conclusion
- training과 decoding이 다른 것을 확인함
- 두 가지 decoding 방식을 다룸: greedy & beam search
- beam search가 일반적은 더 나은 결과를 달성하는 반면 완벽하지 않고 exposure bias에 고통받음
- 훈련 동안, 모델은 절대 오류에 노출되지 않음!
- 모델은 또한 loss-evaluation mismatch로 고통을 받음
- 모델은 token-level cross entropy에 최적화되어 있음
728x90반응형'Natural Language Processing' 카테고리의 다른 글
5 Text Decoding Techniques (0) 2022.02.24 Masking and padding with Pytorch (0) 2022.02.23 Word2Vec (word embedding) (0) 2022.02.09 기계 번역에서 alignment 의미 (0) 2022.01.25 GPT2 vs XLNet (0) 2022.01.13