-
빅데이터분석기사 실기 준비 - Day 2자격증/빅데이터분석기사 2021. 11. 25. 07:02728x90반응형
1. 단변량 데이터 탐색
- df.info() 를 통해 컬럼 개수와 자료형을 알 수 있음

- replace를 통해 범주 이름을 바꿀 수 있음

- 그래프 그리기
kind를 line or bar로도 바꿀 수 있음
- df.describe() 통해 모든 변수의 기술 통계량 확인하기

roe 변수는 mean과 50%(중위수) 간의 차이가 적으니 이상치가 적다고 볼 수 있음
salary, sales는 mean과 중위수 간이 차이가 다소 크므로 이상치가 많다고 볼 수 있음 - 왜도(skewness) 첨도(kurtosis)
아래 사진 사이트: https://digitaschools.com/descriptive-statistics-skewness-and-kurtosis/
왜도: 그래프의 좌우 대칭, 음수면 오른쪽에 자료가 더 많고 이상치는 작은 값들이 있을 것이고 양수면 왼쪽에 자료가 더 많고 이상치는 큰 값이 많다고 볼 수 있음
첨도: 그래프 뾰족한 정도, 값이 클수록 중심에 자료가 많이 몰려있다는 것을 의미
왜도를 보면 salary, sales 모두 2보다 크고 양의 값으로 우측으로 꼬리가 긴 분포일 것임
- 기타


- 히스토 그램 df.hist() or df['변수명'].hist()

salary, sales 모두 매우 이상치 값이 존재
이러한 이상치 문제를 해결하려면 제거(delete), 변환(transform) 적용해야 함
2. 이변량(두 변수) 데이터 탐색
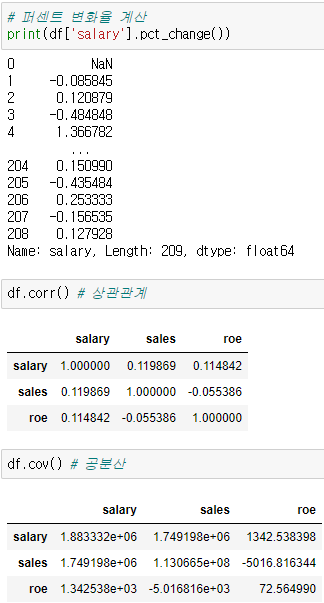
- df.corr() 혹은 산점도(plt.scatter(x, y))를 통해 확인
- industry 범주 별로 salary(종속변수)의 평균 및 기술 통계량을 파악하기 위해 groupby 함수 이용

3. 이상치 처리
- box plot을 통해 확인

- IQR 기준으로 이상치 처리하기
IQR*1.5 보다 크거나 작은 값 제거
- 이상치 제거 후 hist(), 상관관계, 산점도 확인


- 각 변수에 대한 이상치를 IQR을 통해 제거한 후 상관계수와 히스토그램 확인한 결과
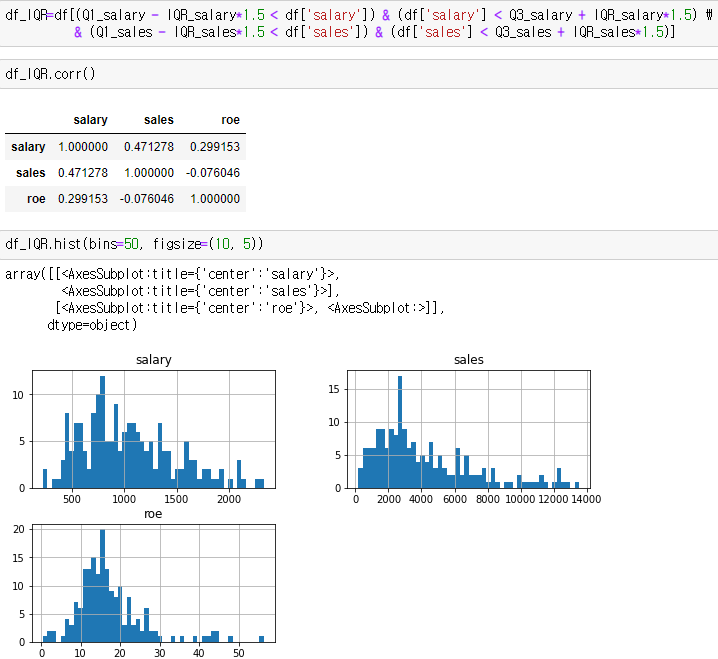
728x90반응형'자격증 > 빅데이터분석기사' 카테고리의 다른 글
빅데이터분석기사 실기 준비 - Day 5 (2) (0) 2021.12.01 빅데이터분석기사 실기 준비 - Day 5 (1) (0) 2021.11.30 빅데이터분석기사 실기 준비 - Day 4 (0) 2021.11.30 빅데이터분석기사 실기 준비 - Day 3 (0) 2021.11.26 빅데이터분석기사 실기 준비 - Day 1 (0) 2021.11.24 - df.info() 를 통해 컬럼 개수와 자료형을 알 수 있음